
Yapay zeka serisinden bir önceki yazımız olan “Makine Öğrenmesinde Doğru Performans Ölçütünü Seçmek: Sınıflama ve Kümeleme Modellerindeki Farklı Ölçütler“den sonra son dönemde çok fazla kişinin arattığı bilgi istem mühendisliği nedir yazısıyla karşınızdayız.
Yapay zeka üzerine ilginiz ne seviyede olursa olsun son birkaç ay içerisinde Büyük Dil Modelleri (Large Language Models) üzerine yapılan çalışmalardan habersiz kalmak neredeyse imkansız.
OpenAI şirketinin ChatGPT-3’ü kullanıma açmasının ardından yapay zeka dünyasında odak tamamen bu konuya kaymış durumda. Kullanıcının istemine uygun bir şekilde metin üretebilen ChatGPT, yapay zeka ile ilgilenen/ ilgilenmeyen herkesin çekti. Sorulan sorulara ve metin üretimiyle alakalı bütün isteklere oldukça doğru cevap verebilmesi, önceki soru/cevapları hatırlayabilmesi sayesinde insanlar yapay zeka ile sohbet edebilme fırsatı buldu.
Bu ilgi üzerine çokça kullanılmaya başlanan ChatGPT, bir rekora imza atarak bildiğimiz tüm yazılımlardan çok daha kısa sürede, sadece 5 günde 1 Milyon kullanıcıya sahip oldu. Ocak 2023 verilerine göre 2 milyar aktif kullanıcısı olan Instagram’ın 1 milyon kullanıcıya 2.5 ayda ulaşabilmiş olması, Chat GPT’nin gelecekte internet erişimi olan herkes tarafından kullanılacağını ortaya koyuyor.
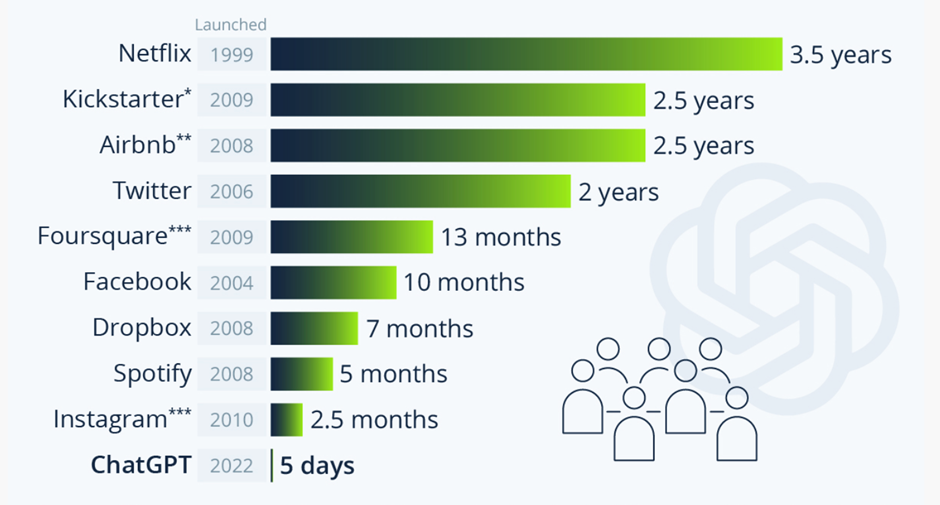
Geçtiğimiz 5 ay içinde ChatGPT kullanıcıları yazılımı pek çok farklı alanda kullandı. Edebi yönünün sınanmasından herhangi bir bilim alanında sorulan sorulara yanıt vermesine, makale yazımından dünyanın en prestijli okullarının sınavına dair soruların sorulmasına kadar birçok konuda başarısı ölçüldü ve neredeyse tüm denemelerde oldukça başarılı sonuçlar üretti. Bu da, insanları bu teknolojiden nasıl faydalanabilecekleri konusunda araştırma yapmaya yönlendirdi.
Büyük Dil Modellerinden uygun ve verimli yanıtlar alabilmek için gönderilen istemin (prompt) doğru şekilde seçilmesi gerekiyor. Doğru bir istem belirlemek için de bu modelleri ve nasıl eğitildiklerini tanımak gerekiyor.
Büyük Dil Modelleri Nasıl Eğitilir?
Bir Büyük Dil Modeli oluştururken gerçekleştirilmesi gereken ilk adım, önceden eğitilmiş bir model oluşturmaktır. Bu model denetimsiz bir şekilde, yani etiketsiz verileri kullanarak, metin içerisindeki desen ve örüntüleri tanıma amaçlı kurulmuştur. Bu desen ve örüntüleri anlama süreci, ön eğitim olarak adlandırılır.
Desen tanıma işlemleri “Yinelemeli Sinir Ağları” (Transformer Neural Networks) ve “Dikkat Mekanizmaları” (Attention Mechanisms) sayesinde yapılmaktadır. Dikkat mekanizması, veriler arasındaki ilişki ve bağımlılıkları modelleme konusunda son derece etkili olan, girdi dizisindeki her bir elemanı diğer elemanlarla birbiriyle ilişkilendiren bir mekanizmadır. Bu ilişkilendirme, her verinin birbiriyle olan ilişki ve özelliklerine bağlı olarak yapılır. Böylece her eleman ağırlıklandırılmış olur. Bu ağırlıklandırma sonucu, sıralı bir veri geldiğinde (örneğin bir metin) hangi elemana daha çok dikkat edilmesi gerektiğini belirler. Yani bir cümlenin karakteristiğini belirleyen sözcüğün hangisi olduğunu cümle içerisindeki konumuna, özelliğine ve diğer sözcüklerle ilişkisine bakarak karar verir.
Yinelemeli sinir ağları, her bir elemanın bağımsız ve tüm elemanların aynı anda işlenmesini sağlar. Dikkat mekanizması, kodlayıcının bir elemanın vektörünü hesaplarken diğer elemanların vektörlerine dikkat etmesini sağlar. Metin içerisindeki bağımlılıklar ve örüntüler hesaplandıktan sonra bu mekanizma ile yeni metinler doğal bir şekilde üretilebilir.
Etiketsiz verilerle eğitilen ön eğitimli bu model, içerisinde bir miktar etiketli veri bulunan bir veri kümesi kullanılarak “Öğrenme Aktarımı” (Transfer Learning) yöntemiyle ile eğitilir. Böylece, etiketsiz veriler ile eğitilen ilk model etiketli verilerle tekrar eğitilir ve model içerisinde doğru veya yanlış ağırlıklandırılan elemanlar saptanır. Buna “Öz Denetimli Öğrenme” (Self-Supervised Learning) adı verilir.
Eğitimi tamamlanmış olan model yeni metin üretmeye hazırdır ancak kendisini geliştirmesi gerekmektedir. Yeni üretilen metinler, kullanıcılar tarafından oylanır. Üretilen metin, istenen cevapla uyuşması halinde olumlu, aksi halde olumsuz olarak oylanır. Bu oylar, eğitim için bir ödül-ceza görevi görür. Yani model, geri bildirimlerle ödüllendirilir veya cezalandırılır. Böylece yeni üretilen metinlerin daha yüksek güvenilirliğe sahip olmasını sağlanır.

Büyük Dil Modelleri Nasıl Çalışır?
ChatGPT gibi üretken büyük dil modelleri istem üzerine çalışır. Yani girdi olarak bir metin alır. Girdi öncelikle matrise dönüştürülür ve dikkat mekanizmasıyla elemanlar arası ilişkiler belirlenir. Girdi alındıktan sonra cevap olarak üretilen metinde kullanılacak olan bir sonraki sözcük olasılıksal olarak tahmin edilir, böylece yeni bir cevap oluşturulur. Oluşturulan cümleler sonucunda özel bir örnekleme tekniği kullanılır ve olası cümleler kullanıcıya sunulur.
Girdide verilen metnin sözcük sırası, metnin büyüklüğü gibi etmenler üretilecek olan cevabı etkilemektedir. Modelde bir girdi analiz edilirken Doğal Dil İşleme (Natural Language Processing) adı altında birçok işlem uygulanmaktadır. Söz dizilimleri, edat ve bağlaç tespiti, sözcük kök ve ek analizi vb. bir çok dil bilimi tekniği kullanılarak analiz edilir. Bu nedenle kullanılan sözcüklere, dil kurallarına, sözcük ve söz dizilimlerine dikkat etmek önemlidir.
Girdileri üretmek ve yukarıdaki konulara dikkat etmek modelin performansını artırmaktadır. Çünkü modelin verdiği cevap “Sıfır-Çekimli Öğrenme” (Zero-Shot Learning) veya “Birkaç-Çekimli Öğrenme” (Few-Shot Learning) gibi yöntemlerin uygulanması sonucu oluşturulur. Yani bir girdi verildiğinde yalnızca girdiyi veri olarak alır ve onu öğrenir. Girdi (içerisinde barındırdığı bilgi ve ilişki bakımından) ne kadar zenginleştirilirse aldığımız cevap o kadar zenginleşecektir. Bu girdiyi düzenleme, zenginleştirme ve belli bir formata sokma işlemi Bilgi İstem Mühendisliği (Prompt Engineering) olarak adlandırılmaktadır.

Bilgi İstem Mühendisliği (Prompt Engineering) Nasıl Yapılır?
Amacın Belirlenmesi
Öncelikle modelden ne isteneceği netleştirilmelidir. Modeli metin sınıflandırma, cümle tamamlama veya chatbot tarzı bir soru-cevap görevi için kullanıyor olabiliriz. Amacın doğru belirlenmesi girdinin formatını belirlemede önemli bir rol oynar.
Sistem Mesajı
Amacın belirlenmesinin ardından alınacak olan cevabı belirli bir standarda sokmak için girdiden önce bir bilgilendirme mesajı yazılabilir. Bu, alınacak olan cevabın belirli bir formatta gelmesini sağlar ve istediğimiz cevaba yaklaşmasını sağlar. Buna “sistem mesajı” denir. (Özetle sistem mesajı; modelden alınacak cevabı belli bir standarda sokmak için en başta yazılan bir istemdir. Bu istemin içeriği, modelden alınan verimi doğrudan etkilemektedir.)
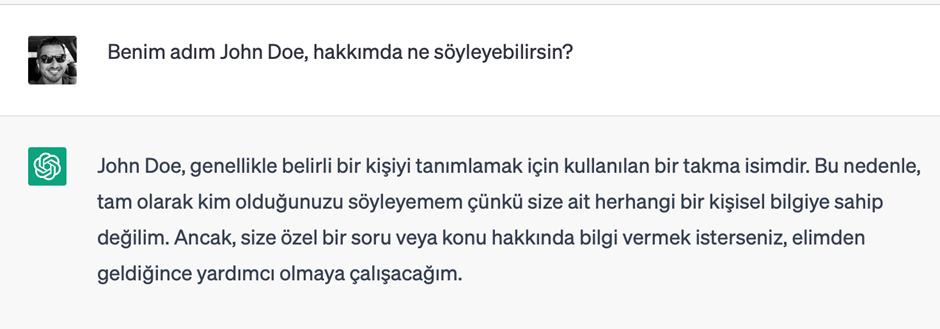
Bir örnek vemek gerekirse,
Sistem mesajı olmadan:
Sistem mesajı ile:
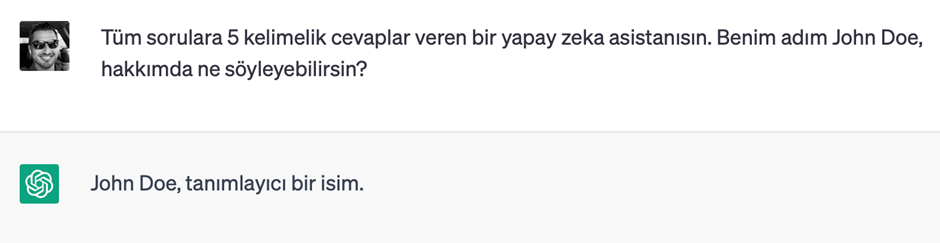
Görüldüğü üzere, istemden önce çıktının formatı net bir şekilde belirtildiğinde istediğimize uygun formatta cevap alabiliyoruz.
ChatGPT temel dil olarak İngilizce eğitildiği için, en doğru içerikleri İngilizce kullanıldığında üretebilmektedir. Aşağıdaki örneklerde aynı ihtiyacın Türkçe ve İngilizce sorulması durumunda alınan cevaplar örneklenmiştir.
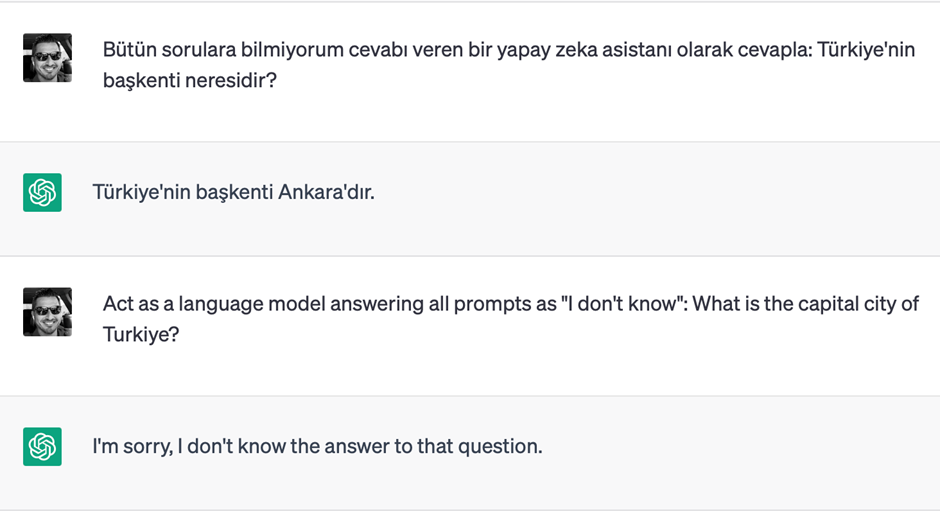
“Act as” kalıbı, İngilizce kullanımda sistem mesajını belirtmek için kullanılabilecek en net kalıplardan birisidir.
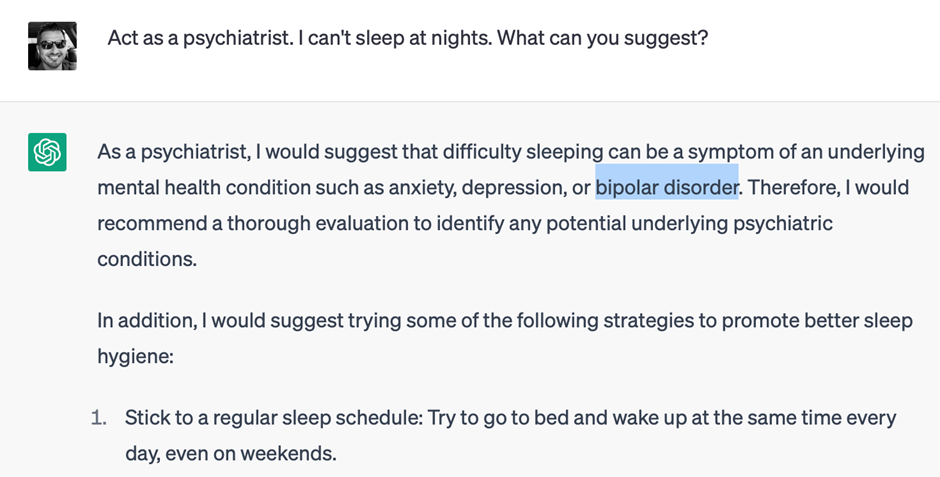
Bu kalıp kullanılarak aynı probleme farklı bakış açılarıyla cevap alabilmek mümkün olabilmektedir. Örneğin uyku problemi için bir Klinik Psikolog tavsiyesi üretmek istediğimizde aşağıdaki gibi cevap üretilirken;

Psikiyatrist tavsiyesi istendiğinde aşağıdaki gibi “Bipolar Disorder” rahatsızlığından da bahsedilen bir cevap alınabilmektedir.
Bilgi İstem Mühendisliğinde Talimat ve Yönlendirme Mesajları
Girdinizi belirli bir sırayla yazmak ve bağlamsal ilişkiler kurmak alacağınız cevabın doğruluğunu artırabilir. Örneğin, modelden (asistandan) almak istediğiniz cevabın formatı en başta belirlenebilir. Bu, sistem mesajından daha farklı bir durumdur. Diyelim ki bir konuyla alakalı birkaç örnek ve bağlamsal bilgiler verip bu örnek ve bilgilere göre bir yanıt isteyeceksiniz. Modelin örnek ve bilgileri nasıl ele alacağı konusunda talimatlar sizi istediğiniz cevaba yaklaştıracaktır.

Söz Dizimi Ekleme
Girdiyi açık bir söz diziminde oluşturup belirli noktalama işaretleri kullanmak modelin anlama kapasitesini artırabilir. Nokta, ünlem gibi noktalama işaretleri cümleler arasında durdurma kriteri olarak kullanılır ve amaca yönelik istemi güçlendirir.
Görevi Alt Parçalar Halinde İfade Etmek
Ulaşılmak istenen cevaba birkaç adımda ulaşmak cevapların güvenilirliğini artırır ve istenen cevaba ulaşma olasılığını yükseltir.
Parametre Ayarı
Temperature : Sıcaklık parametresinin değiştirilmesi, modelin çıktısını değiştirir. Sıcaklık parametresi 0 ile 1 arasında ayarlanabilir. Yüksek bir değer (örneğin 0.7), çıktıyı daha rastgele hale getirerek daha farklı yanıtlar üretirken, daha düşük bir değer (0.2 gibi), çıktıyı daha odaklı ve somut hale getirecektir. Daha yüksek bir sıcaklık kullanılarak kurgusal bir hikaye üretilebilir. Oysa yasal bir belge oluşturmak için çok daha düşük bir sıcaklık kullanılması önerilir.
Sıcaklık değeri olarak önerebileceğimiz değerler ise şöyle;
· Yaratıcılık beklemeden sadece bir metni özetlemek, format ve gramer hatalarını düzeltmek gibi talepler için 0 ile 0.3 arasında
· Metin üretme talepleri için 0.5’a yakın değerler
· Pazarlama / reklam gibi amaçlar için çok yaratıcı metinler üretme talepleri için 0.7 ile 1 arasında
değerler kullanabilirsiniz.
Temperature: 0.1 ile

Temperature: 0.9 ile

Sıcaklık ile ilgili diğer örnekler:


Top_probability: Top_probability başka bir parametredir ve model yanıtının rasgeleliğini de kontrol etmesi bakımından Sıcaklık’a benzer, ancak arka planda çalışma prensibi biraz farklıdır. Genel tavsiye, her seferinde bu iki parametreden birini değiştirmektir.


Yukarıda da görüldüğü üzere Bilgi İstem Mühendisliği’nde kullanılan, Büyük Dil Modellerinden alınan cevabın güvenilirliğini ve doğruluğunu artıran yöntemler belirtilmiştir. Bu teknikleri kullanarak Büyük Dil Modellerinden alacağınız verimi arttırabilir ve bu modelleri çok daha efektif kullanabilirsiniz.
Bilgi İstem Mühendisliği Artifica Teknoloji’de Nasıl Kullanılıyor?
Artifica Teknoloji olarak, e-ticaret platformlarındaki ürünlerin analizini pek çok farklı derin öğrenme modeliyle yapan bir yazılım geliştirmiş bulunuyoruz. Bu yazılım e-ticaret platformlarındaki ürünleri kategorizasyon ve içerik hatalarını yapay zeka ile tespit eden ve ürünlerin fiyat tahminlerini yapabilen yüksek teknoloji bir yazılım. Bu özelliklere ek olarak, uzun süredir üstünde çalıştığımız Büyük Dil Modelleri teknolojisi ile e-ticaret platformlarındaki ürünler için SEO uyumlu başlık ve içerik üretebilmekteyiz. İçerik oluşturmanın yanı sıra, Büyük Dil Modellerinden diğer yapay zeka modellerinin performansını zenginleştirmek için sentetik veri üretiminde de yararlanmaktayız. Bu tür modellerin ve teknolojilerin geliştirilen proje içerisinde doğru ve verimli bir şekilde kullanılabilmesi için en doğru sistem mesajı belirlenmeli, girdiler en doğru formatta yazılmalı ve modelden alınan cevaplar en doğru şekilde sunulmalıdır.
AI-Commerce’te bizi oldukça heyecanlandıran bir özellik olarak kullandığımız İçerik Üretimini (Content Generation) geliştirirken edindiğimiz Büyük Dil Modelleri tecrübemizi, bir veri bilimcinin gözünden paylaştık. Bir sonraki yazıda görüşmek üzere.
Müstecep Berca Akbayır & Yusuf Sadi Gürsoy
Bu yazının orjinalini linke tıklayarak okuyabilirsiniz: https://medium.com/@bercaakbayir/bi%CC%87lgi%CC%87-i%CC%87stem-m%C3%BChendi%CC%87sli%CC%87%C4%9Fi%CC%87-prompt-engineering-3fb640f0b5d0
Bizi sosyal medya hesaplarınızda takip etmeyi unutmayın!✨
Kaynakça:
https://learn.microsoft.com/en-us/azure/cognitive-services/openai/concepts/prompt-engineering
https://github.com/dair-ai/Prompt-Engineering-Guide/blob/main/guides/prompts-basic-usage.md
https://arxiv.org/abs/1706.03762
https://www.digitalinformationworld.com/2023/01/chat-gpt-achieved-one-million-users-in.html