Gün içerisinde birçok problemle karşılaşıyoruz ve bu problemleri çözerken daha önceki deneyimlerimizden sıklıkla yararlanıyoruz. Daha önce karşılaştığımız bir probleme benzer bir durumla karşı karşıya kaldığımızda önceki deneyimlediğimiz durumlardan öğrendiklerimizi ve çıkardığımız dersleri son karşılaştığımız durumda biraz duruma göre yorumlayarak yine kullanıyoruz. Bu son karşılaştığımız durumdan öğrendiklerimizi de ileride elbette kullanacağız. Bu şekilde bilgi birikimimiz ve tecrübemiz kümülatif olarak artmakta ve problemlerle karşılaştıkça yaptığımız hataları daha az yapmakta ve deneyim kazanmaktayız. Böylece kendimizi zaman ilerledikçe geliştiriyoruz.
Alan Turing’in “I propose to consider the question, ‘Can machines think?’” (“Makineler düşünebilir mi?” sorusunu ele almayı öneriyorum.) cümlesiyle başladığı ve yeni bir bilim sahasının doğumuna sebep olan makalesinin ardından makinelere insan gibi düşünebilme yeteneğinin kazandırılması konusunda ciddi çalışmalar yapıldı. İstatistiksel ve matematiksel modeller yazıldı, birçok yaklaşım geliştirildi. Bütün bu çalışmaların ardında makinelerin insana benzer bir şekilde düşünebilme yeteneğini kazandırma çabası yatmaktadır. Özellikle son dönemlerde adı çokça duyulan ve makine öğrenmesi modellerinin performansını artırmasıyla adından çokça söz ettiren öğrenim aktarımı (transfer learning) yaklaşımı da yine bu mottoyla geliştirilmiştir.
Yazının başlangıcında da dediğimiz gibi günlük hayatta karışımıza çıkan problemleri çözerken deneyimlerimizden yararlanıyoruz. Böylece problemleri daha kolay çözüyoruz ve hata yapma riskimizi minimize ediyoruz. Örneğin, bisiklet sürmeyi öğrenirken bir çok problemle ilk kez karşılaşıyoruz. Örneğin dengede kalma, çevre kontrolü, bisikleti kontrol etme ve tüm bunları yaparken de pedalı çevirmeye devam etme… Bütün bu becerileri aynı anda ilk kez öğreniyoruz. Bisiklet sürmeyi öğrenmemizin ardından motosiklet öğrenmek istediğimizde öğrenme sürecimiz bisiklet sürmeyi öğrendiğimiz zamana göre çok daha az zorlayıcı olacaktır. Çünkü bisiklet sürerken edindiğimiz dengede kalma, araç ve çevre kontrolü gibi edindiğimiz becerileri motosiklet sürerken de kullanıyoruz. Böylece öğrenme sürecimiz daha hızlı ve kolay oluyor.

Makine öğrenmesi sürecinde de bu tarz bir yaklaşımı ‘öğrenme aktarımı’ ile gösterebiliriz. Teknik olarak süreç aynı şekilde işlemektedir. Makine öğrenmesi modelini belli bir problem özelinde geniş bir veri setiyle eğitildikten sonra modelde güncellenen parametreler saklanır. Saklanan bu parametreler, çözülen bu probleme benzer veya ilişkili görülen bir problemi çözmek için kurulan makine öğrenmesine verilir. Bir önceki problemin bilgilerini taşıyan model yeni olan problemi tanıyarak çözmeye çalışır. Böylece sıfırdan model kurmadan daha kısa sürede daha başarılı sonuçlar üretilir.
Makine öğrenmesi dünyasında öğrenme aktarımı ile oldukça başarılı sonuçlar elde edilmiştir. Ayrıca mevcut problemleri başarıyla çözmesinin yanı sıra genel yapay zekaya ulaşma serüveninin önemli adımlarından biri olarak tanımlanmaktadır.
Öğrenme aktarımını kısaca tandıktan sonra gerçek hayat problemlerine uyarlamasını inceleyebiliriz. Ama önce bazı teknik konulara hakim olunmalı ve bu yaklaşımın teknik kısımları bilinmelidir.
Yapay Sinir Ağlarının Temelleri
Beyin hücrelerinden (nöron) ilham alınarak geliştirilen bu matematiksel model, 2000’lerin başına kadar bilgisayarların çok gelişmemiş olmasından kaynaklı olarak bu modelden verimli bir şekilde yararlanılamadı. Ancak özellikle son dönemlerde bilgisayarların işlem performanslarının artmasıyla yapay sinir ağları birçok problemin çözümünde kullanılıyor ve yeni yaklaşımlarla geliştirilmeye devam ediliyor.
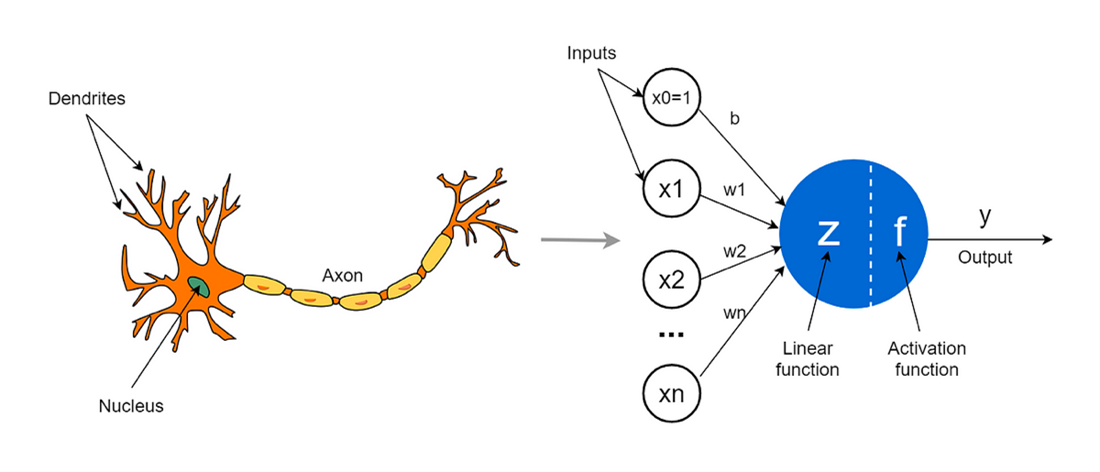
Yukarıda da görüldüğü üzere mimari ve çalışma mekanizması olarak yapay sinir ağları, biyolojik sinir ağlarına oldukça benzemektedir. Dendritlerden alınan elektriksel sinyaller gövdeden geçerek akson boyunca uçtaki dendritlere iletilir ve bir sinir hücresindeki elektriksel sinyalin geçişi tamamlanır. Yine aynı şekilde yapay sinir ağlarında girdi olarak mevcut bilgiler gelir. Wn olarak tanımladığımız ağırlıklarca toplam fonksiyona (yukarıdaki şemada linear function olarak adlandırılan kısım) iletilir. Burada toplam fonksiyonunda stratejiye bağlı olarak ortalama fonksiyonu, medyan fonksiyonu gibi doğrusal fonksiyonlar kullanılır ve bu noktada bütün ağırlıklandırılmış bilgiler birleştirilir. Birleştirilen bilgiler belirli bir eşik değer atamasının yapılacağı aktivasyon fonksiyonuna iletilir ve niyahetinde bir çıktı değer elde edilir. Çeşitli mimarilerce bu sinir ağları tekrar ve tekrar çalıştırılır.
Sinir ağlarında geri yayılım (backpropagation):
Geri yayılım algoritması, yapay sinir ağının ürettiği sonuç olan tahmin edilmiş değeri gerçek veriyle kıyaslar ağın hata fonksiyonunu elde eder.Bu fonksiyon sayesinde ağın hata miktarını hesaplar ve ağın doğruluğunu artırmak için bu hataya göre ağırlıklar atanır.Gradyan iniş algoritması (gradient descent algorithm) ile ağın ağırlıkları optimize edilir. Her iterasyonda bu işlemler tekrarlanır ve ağırlıklar güncellenir.
Öğrenme Aktarımı (Transfer Learning)
Yazının başlangıcında da belirtildiği gibi öğrenme aktarımı, bir problemin çözümünde edinilen bilgileri başka bir problemde kullanılması ve tecrübelerin aktarılmasıdır. Örneğin bir görüntü sınıflandırma projesi için çalıştığımızı varsayalım. İlk problem olarak ultrason görüntülerinden kanser teşhisi koymaya çalıştığımızı varsayalım.
Elimizde Sağlık Bakanlığı’ndan temin ettiğimiz Türkiye genelini temsil eden büyük bir veri olduğunu varsayalım. Probleme uygun bir sinir ağı modeli kurduk, sıfırdan eğittik ve güncellenen ağırlıkları sakladık. Şu an elimizde büyük bir veriden öğrenen güçlü bir yapay sinir ağımız ve onun eğitim süresince güncellenmiş ağırlıkları var. Bunun anlamı şu an sinir ağı bu problem üzerinde bir deneyime sahip olduğudur. Ardından bir hastaneden görece olarak daha düşük bir boyutta veri temin ettik. Bu veriyle modeli sıfırdan eğitmek yerine bu problem için kurulan sinir ağına önceki problemde güncellenen ağırlıkları verdiğimizde çok daha iyi bir başlangıç noktası olacaktır.
Bu problem üzerinde tecrübe edinmiş olan sinir ağı daha az veri görmüş olmasına karşın oldukça iyi bir sonuç verecektir. Böylece önceden öğrenilen bilgiler burada kullanılmış olup tecrübe aktarılmıştır.
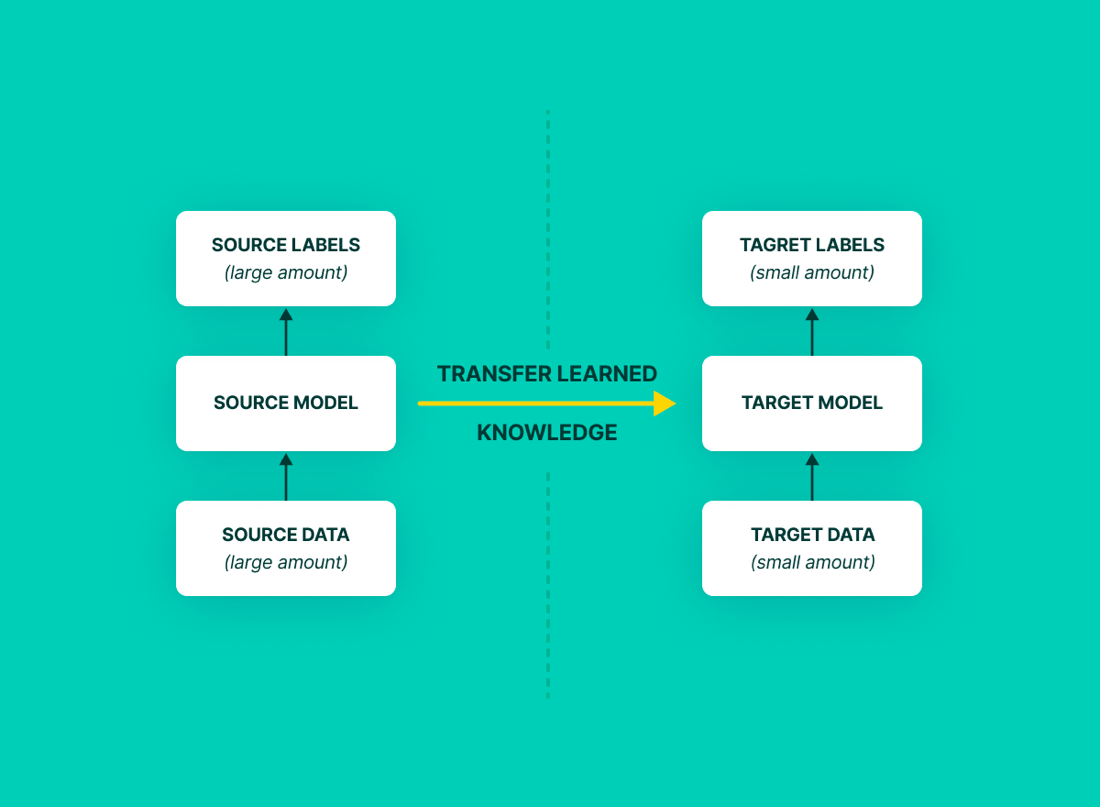
Öğrenim Aktarımı Çeşitleri
Öğrenim aktarımının genel bir problemi makine öğrenmesi metotlarıyla çözdükten sonra daha özel bir problem üzerinde edinilen tecrübenin aktarılmasıyla problemi çözme stratejisi olduğundan bahsettik. Bu süreç içerisinde karşılaşılan bazı senaryolar vardır.
İlk modeli üretirken çözmek istediğimiz problem ile öğrenme aktarımı ile çözmek istediğimiz problem aynı veya ilişkili olabilir ancak buna karşın bu iki problemin çözümünde kullanacağımız veriler farklı olabilir. Buna Dönüştürücü Öğrenme denmektedir. Örneğin yukarıda verdiğimiz ultrason görüntülerinden kanser tespiti örneği bir dönüştürücü öğrenme çeşididir.
Bir diğer senaryoda ise ilk modelin üretildiği problemle öğrenme aktarımının uygulanmak istenen problemin farklı olmasıdır. Örneğin ImageNet ile bir model eğitmek istediğimizi varsayalım. ImageNet, içerisinde milyonlarca görselin ve binlerce farklı kategorinin bulunduğu bir veri setidir.
Oldukça geniş ve genel bir veri setinden bahsetmekteyiz. Bu veri setini kullanarak oluşturduğumuz bir yapay sinir ağını hayvan görsellerini tahmin etmek üzere kullandığımızı düşünelim. İlk modelimizi oluşturmuş olduk ve problemimizi çözdük. İkinci safhada ise insan yüzlerini tanıyan bir model üretmemiz istendi. İlk problemde hayvanları sınıflandıran bir modelden edinilen bilgileri şimdi insanları sınıflandıran bir problem için kullanıyoruz. Buna da tümevarımsal öğrenme (inductive learning) denmektedir.
Öğrenim Aktarımı Mimarisi:
Öğrenim aktarımını uygularken oluşturulması gereken bir mimari yapı vardır. Adım adım mimariyi inceleyecek olursak:
1. Önceden Eğitilmiş Modeli (Pre-trained Model) Seçmek
Bazı geliştiriciler tarafından önceden büyük bir veri setiyle eğitilen ve geliştirmeye açık bir şekilde paylaşılan bazı modeller mevcuttur. Sıklıkla kullanılan bazı önceden eğitilmiş model çeşitleri şunlardır:
VGG:
Oxford Üniversitesi’nde bir grup araştırmacı tarafından üretilen model, 16 ve 19 katmanlı olmak üzere iki çeşiti mevcuttur. VGG, özellik çıkarımı ve sınıflandırma için kullanılan bir mimaridir ve görüntü sınıflandırma alanında bir dönüm noktası olarak kabul edilir. Imagenet yarışmasında oldukça iyi sonuçlar üreterek adını duyuran VGG modeli, görüntü işleme alanında çalışma yapan birçok geliştirici tarafından tercih edilmiştir.
ResNet:
Residual Networks (ResNet) adındaki bu model Microsoft uzmanlar tarafından üretilmiş olup geliştiricilere açık bir şekilde paylaşılmıştır. Esas olarak aşırı öğrenme problemine çözüm olarak gelişitirilmiştir ve klasik sinir ağlarına kıyasla çok daha fazla katmana sahiptir. Ancak katman fazlalığından dolayı yine aşırı öğrenmeye yatkındır. Bundan dolayı artık blok adı verilen bir strateji barındırır. Blok içerisinde girdi ve çıktıları birbirine bağlayarak kısa yollar oluşturur. Çıktılar, girdilere eklenmiş olur ve yeni özellikler tanınmış olur. Görüntü işleme alanında en çok tercih edilen modeldir.
Inception / Xception:
Google uzmanları tarafından geliştirilen bu model, en çok tercih edilen modeller arasında yer almaktadır. Xception, VGG ile Inception modellerinin birleşiminden meydana gelir ve klasik sinir ağlarına kıyasla daha yüksek doğruluğa ve daha düşük hesaplama maliyetine sahiptir. Görüntü işleme, sınıflandırma ve nesne tespitinde sıkça tercih edilir.
2. Katmanları Dondurma (Freezing) ve Yeni Katmanları Eğitme
Önceden eğitilmiş modeli seçtikten sonra yapılması gereken işlem probleme özgü özellik çıkarımı ve katmanları dondurma işlemidir.
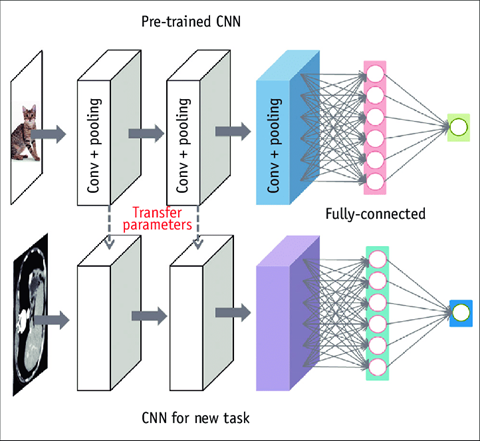
Yukarıda basitçe görüldüğü üzere bir evrişimsel sinir ağı modeli 3 kısımdan oluşmaktadır. Giriş katmanı, saklı (orta) katmanlar ve çıkış katmanı. Son aşamada tam bağlantı yapılarak evrişimsel sinir ağlarının kurulumu tamamlanır. Önceden eğitilmiş modellerde genel mantık, ilk ve orta katman olduğu gibi tutulur ve son katman probleme özgü olarak yeniden yazılır. Bu noktada yeni problemimiz için önceden eğitilmiş modeli kurduktan sonra parametreleri transfer ederiz. Böylece ilk 2 katmanda güncellenmiş parametrelerimiz olmuş olur.
Kurulan önceden eğitilmiş modele ek olarak son bir katman daha yazılır. Bu son katman, probleme özgü olarak değişmektedir. Son katmanın yazılmasının ardından tam bağlantı kurulur ve mevcut modelimiz tamamlanmış olur. Buradan sonra dikkat edilmesi gereken nokta önceden eğitilmiş modeldeki katmanların dondurulmasıdır. Böylece model, yeni verilerle yeniden eğitildiğinde ilk katmanlardaki bilgi kaybolmamış olur ve yeni verilerle eğitimimiz tamamlanmış olur.
3. İnce Ayar (Fine Tuning)
Bu aşama, öğrenim aktarımı için zorunlu değildir. Ancak birçok senaryoda performansı artırdığı görülmüştür. Katmanlar dondurulup modelin yeni katmanları eğitildikten sonra modelin eğitimi tamamlanmıştır. Bu aşamaların üzerine dondurulmuş olan katmanlar çözünerek (yeniden eğitilebilir hale getirerek) model tekrar eğitilir. Model tekrar eğitilirken sinir ağının öğrenim oranını düşürmek, optimizasyon aşamasında daha detaylı arama yapılması sağlar ve daha yavaş ve detaylı bir öğrenim ile bütün sinir ağı tekrar eğitilir. Bu eğitim, önceki eğitimin üzerine ek olarak tanımlanır ve genel olarak sonuçları iyileştirmektedir.
Öğrenim Aktarımına Neden İhtiyaç Duyulmaktadır ?
Önceden eğitilmiş modelin ağırlıkları, önceki problemlerde edindiği bilgileri ve tecrübeleri barındırmaktadır. Öğrenim aktarımının en büyük avantajı, yeni veriyle sinir ağını sıfırdan eğitmek zorunda olmamamız. Önceden eğitilen sinir ağının üzerine yeni veriyle eğitim yapılarak çok daha iyi bir başlangıç yapılması sağlanıyor. Ayrıca sinir ağlarını başarılı bir şekilde eğitmek için yüksek bir miktarda veriye ihtiyaç duyulmaktadır. Daha az veriyle daha karmaşık problemler, öğrenim aktarımı stratejisiyle mümkün hale gelmektedir.
Artifica Teknolojide öğrenme aktarımı neden kullanıldı?

Artifica Teknoloji, geçtiğimiz günlerde çıkarmış olduğu AI-Commerce adındaki ürününde görüntü işleme ve bilgisayarlı görü, doğal dil işleme ve tabular veriyle sınıflandırma modelleri gibi 9 farklı derin öğrenme modelini bir arada kompoz bir şekilde kullanarak e-ticaret sektöründeki ürünlerin analizini yapmakta ve kategorizasyon hatalarını düzeltmektedir. Bilgisayarla görü alanında yapay zeka modellerini eğitirken öğrenim aktarımına sıkça başvurmaktayız. Artifica Teknolojinin veri tabanında yer alan milyonlarca ürün görseliyle eğitilen konvülasyonel sinir ağları, çeşitli durumlarda tekrardan eğitilmektedir. MLOps ekosistemi içerisinde birçok tetikleyiciyle bu modeller tekrar eğitilir. Eğer sezonluk yeni veri gelirse, modellerin doğruluk oranları düşerse çeşitli stratejilerle veri tabanından veriler tekrardan eğitime tabii tutulur ve modeller güncellenir. Ayrıca, temel model olarak geniş veri setimizle eğitilmiş modellerimiz Artifica Teknolojiden hizmet alan müşterilerimizin bizlere sağladığı verilerle, tekrar eğitime tabii tutulur ve kümülatif bir öğrenme süreci gerçekleşir. Bu sayede zaman geçtikçe yapay zeka modellerinin başarı yüzdesi sürekli gelişmektedir.
Artifica Teknolojide öğrenme aktarımı nasıl kullanıldı?
İlk Deney
AI-Commerce’in ürünlerin doğru kategorizasyonunu yapabilmesi için başarılı bir görüntü sınıflandırma modeline ihtiyaç vardı. İlk olarak artıklardan öğrenebilen bir evrişimsel sinir ağı mimarisi kuruldu. Kurulan evrişimsel sinir ağının mimarisi özet olarak:
Giriş katmanı 60x60x3 boyutunda bir girdi tensörü alır. Giriş katmanının ardından ağ çeşitli evrişimli bloklardan oluşmaktadır.Her blok, bir önceki bloktan gelen bir artık bağlantıya sahiptir ve iki ayrılabilir evrişim katmanı, toplu normalleştirme ve dropout düzenlemesi içerir. Her bloktaki ayrılabilir evrişim katmanlarının filtre sayısı sırasıyla 256, 512 ve 728’den artar. Son katman ise toplu normalleştirme ve global ortalama havuzlama katmanlarının takibiyle tamamlanır. Sınıf sayısına uygun bir şekilde çıktı katmanının yazlmasıyla ağda tam bağlantı tamamlanır. Böylece ağ, eğitime hazır hale getirilmiştir.Yapılan bu çalışma ile daha az hesaplama gücüyle daha yüksek doğruluk amaçlanarak verimli bir ağ modeli tasarlanmak istenilmiştir.
Deneyin diğer adımı olarak veri tabanında yer alan verilere benzer bir şekilde küçük bir veri kümesi seçildi. Modelin bu verilerle eğitilmesi sonucu yüzde 70’e yakın bir doğruluk oranı yakalanmıştır.
Deneyin ikinci kısmında bir önceden eğitilmiş model kurulmuştur. Model olarak ResNet50 seçilmiş olup son katman probleme özgü olarak yeniden tasarlanmıştır. İlk ve saklı katmanlar dondurularak ağırlıklar korunmuştur. En son olarak ise mevcut epoch sayısının yüzde 30’u, öğrenme oranının (learnnig rate) yüzde 10’u olacak şekilde ince ayar adımı tanımlanmıştır. Bunun anlamı, asıl eğitim süreci bittikten sonra mevcut epoch sayısının yüzde 30’u kadar daha eğitim devam edecek ve bu ikinci eğitim aşamasında optimizer asıl eğitimde kullanılan öğrenim oranının onda biri büyüklükte olacak şekilde daha detaylı bir optimizasyon süreciyle eğitim devam edecektir. Deney sonucunda öğrenme aktarımında sıklıkla karşılaşılan bazı problemler meydana gelmiştir. Bu problemler ve çözümleri aşağıdaki adımlarda anlatılmıştır:
Aşırı öğrenme (Overfitting):
Öğrenme aktarımı uygulanırken en çok karşılaşılan problemlerden birisidir. VGG, ResNet, Inception gibi önceden eğitilmiş modeller, katman sayılarından kaynaklı olarak oldukça kompleks modellerdir. Daha az veriyle eğitim amaçlayan geliştiriciler bu modelleri kullanırken aşırı öğrenme gibi sorunlarla karşılaşabilmektedirler. Bu problemi çözmek için izlediğimiz adımlar:
1. Veri Artırma
Veri artırma (data augmentation) adımı, aşırı öğrenme probleminin üstesinden gelmek için uygulanması gereken ilk adımlardan birisidir. Aşırı öğrenme problemi, modelin genelleştirme yeteneğini kaybetmesinin ardından meydana gelmektedir. Bu adımda, her bir görseli 0.2 radyan ile döndürerek birer kopya oluşturur ve eğitime dahil ederiz. Farklı açılardan gösterilen görseller modelin genelleştirme yeteneğini artırmaktadır.

2. Bırakma (Dropout)
Bırakma (dropout), bir düzenlileştirme tekniğidir. Her katmanda nöronlardan geçen bilginin bir kısmı bırakılır, diğer bir tabirle “unutulur”. Böylece herhangi öğrenilen bir özelliğe fazla dayanmadan eğtiim süreci devam eder. Saklı katmanlarda bırakma oranının yaklaşık yüzde 50 civarında olması önerilmektedir.
3. Erken Durdurma (Early Stopping)
Sinir ağlarında eğitim devam ederken modelin doğruluğu artmayabilir veya artmasına karşın hatalar minimize edilemeyebilir. Bu noktada aşırı öğrenme problemi başlamış demektir. Eğitim süresince eğer ardışık 3 epochta bu durum gözlenirse eğitim orada kesilir ve aşırı uyum başlamadan eğitim tamamlanır.
Patlayan Gradyan (Exploded Gradient) Problemi:
Derin öğrenmede, öğrenme sürecinde yapay sinir ağının geri yayılım sürecinde gradyanın çok büyük olmasından kaynaklı olarak patlayan gradyan problemi ortaya çıkar. Bundan dolayı ağırlık güncellemelerinin çok yüksek bir değerle olması uçta çok yüksek ağırlıkların birikmesine neden olur ve model kararsız hale gelir.
Eğer sinir ağı modelinizi eğitirken eğitim süresince loss (kayıp) değeriniz çok yüksek çıkıyorsa veya NaN değerini veriyorsa patlayan gradyan problemi var demektir. Ağırlıklar çok yüksek değer aldıktan sonra kayıp fonksiyonu minimize edilemez, kullanılan optimizasyon algoritması (adam, rmsrop vb.) çözüm uzayında global maksimumu bulmakta zorlanır ve çözüm uzayında salınım hareketi yapmaya başlar. Bu problemin çözümü için aşağıdaki yollar izlenmiştir :
1. Daha düşük öğrenme oranı:
Bir sinir ağını eğitirken amacımız geri yayılım (back propagation) süresince ağırlıklar ağda güncellenirken kayıp (veya maliyet) fonksiyonunu minimize etmeye çalışırız. Eğer öğrenme oranını düşürürsek ağırlıkların güncelleme oranını düşürürüz, böylece gradyanların aşırı büyüme ihtimalini düşürmüş oluruz.
2. L1 (lasso) ve L2 (ridge) Düzenlileştiricileri:
L1 ve L2 düzenlileştiricileri, aşırı öğrenme problemlerinde modelin veriyi daha iyi genelleştirmelerine olanak sağlayan düzenlileştirme metotlarıdır. Patlayan gradyan problemi için üretilen bir çözüm değildir ancak dolaylı yoldan problemin çözümüne yardımcı olmaktadırlar. L1 ve L2 düzenlileştiricileri, modeli daha küçük ağırlıklar kullanmaya ve gradyanların genel büyüklüğünü azaltmaya teşvik eden kayıp fonksiyonuna bir ceza terimi ekleyerek bunu önlemeye yardımcı olabilir.
Önceden eğitilmiş modeli kurup öğrenme aktarımı uyguladıktan sonra karşımıza çıkan problemler ve bunları nasıl çözdüğümüz yukarıda detaylıca anlatılmıştır. Bu çözüm yollarını uyguladıktan sonra modelimiz yüzde 90’lara varan bir başarı elde etmiştir.
Kendi tasarladığımız sinir ağı mimarisini ve önceden eğitilmiş modeli öğrenme aktarımı metotuyla ayrı olarak eğittikten sonra deneyimiz tamamlanmıştır.
Deneye İlişkin Sonuç ve Karşılaştırma
Her iki model karşılaştırıldığında farkları model kurulumu, eğitim süreci ve sonrası olmak üzere incelenebilir. Sıfırdan bir sinir ağı tasarlayıp kurmak ve ağın deneyini yapmak çoğu zaman maliyetlidir. Uzun süren bir sinir ağı mimari tasarımının ardından beklenen sonuç gelmeyebilir ve daha iyi sonuçlar çıkarmak için parametrelerde ve mimaride düzenlemeler yapılarak beklenen sonuca yaklaştırılabilir. Önceden eğitilmiş modellerin kullanılmasıyla sinir ağlarının kurulumu da oldukça kolaylaşmıştır. Başarısını kanıtlamış çok katmanlı sinir ağlarıyla çalışmak ve yönetmek, bize oldukça zaman tasarrufu sağladı. Öğrenme aktarımı metotuyla eğitilen önceden eğitilmiş sinir ağı modeli ResNet50, daha az veriyle eğitildiği için model karmaşıklığına rağmen eğitimi oldukça kısa sürdü. Ayrıca daha kısa sürede daha yüksek doğruluk oranı yakalandı. Sonuç olarak öğrenme aktarımı kullanılarak zaman ve başarı bakımından daha optimize modeller elde ettik.
Ürün İçerisinde Testlerinin Yapılması
İlk deneyde Ar-Ge çalışmalarında mevcut yöntemin ürünlerin tahminlerindeki başarısının görülmesi üzerine ürün içerisinde denenmek üzere çalışmalara başlandı.
Ürün içerisinde verilerin çeşidi ve boyutu değiştiğinden dolayı yeni bir deneysel sürece başlanmış oldu. Bundan dolayı birkaç farklı model denendi. İlk safhada önceden eğitilmiş modellerin arasındaki farklı kıyaslamak amacıyla ullanılan modeller ResNet50, VGG16 ve Xception modelleridir. ResNet50 ve Xception arasında bariz bir fark olmamasına karşın diğer modellere kıyasla çok daha iyi sonuçlar vermiştir. ResNet50’nin yaklaşık %90, Xception’un ise %91–93 bandında bir doğruluk oranı verdiği görülmüştür. Böylece en iyi performansı gösterenin Xception olduğuna karar verilmiştir.
İkinci safhada ise ürün içerisinde önceden kullanılan ve yukarıda da bahsedilmiş olan konvülasyonel sinir ağı ve en iyi sonucu veren Xception modeli denenmiştir. Deneyde bir ikili (binary) sınıfa sahip veri seti, bir de 4 adet sınıfa sahip bir veri seti seçilip deneylere başlanmıştır.
İkili sınıfa sahip olan veri setinde konvülasyonel sinir ağı yaklaşık %81 doğruluk oranı vermiştir. Yine aynı veri seti üzerinden Imagenet üzerinden eğitilmiş ve güncellenmiş parametreler Xception modeline verilerek tekrar eğitilmiştir. Xception’un doğruluk oranının %91 olduğu görülmüştür.
4 adet sınıfa sahip veri setinde yazdığımız konvülasyonel sinir ağı %70, Xception modeli ise %91.2 doğruluk oranı vermiştir.
Ürün Testlerinde Sonuç ve Karşılaştırma
Ürün içerisinde önceden kullanılan konvülasyonel sinir ağı ile Xception modeli kıyaslandığında bariz farklılıklar görülmektedir. Bu farklılıklardan ilk göze çarpanı doğruluk oranlarındaki fark olduğu görülmektedir. Xception modelinin bizim tarafımızdan tasarlanan konvülasyonel sinir ağına kıyasla yüzde 25 daha iyi sonuçlar verdiği görülmüştür.
Ürün İçerisindeki Etkisi:
Xception modelini ürün içerisine yerleştirdikten sonra yüzlerce kategori üzerinde eğitilmiştir. Yüzlerce kategorinin bu modelle eğitilmesinin ardından öğrenme aktarımının modelin ürün içerisindeki başarının oldukça yükselttiği görülmüştür. Doğruluk oranı olarak belirlenen eşik değerin altında kalan kategorilerden birçoğunun eşik değeri geçtiğini ve başarılı olarak işaretlendiği görülmüştür. Verisi az olan kategorilerin doğruluğu düşük iken öğrenme aktarımı uygulandıktan sonra yüksek bir başarıya ulaştığı görülmüştür. Yapılan geliştirmelerin ardından geçmişe kıyasla daha az aşırı öğrenme problemiyle karşılaşılmaya başlanmıştır.
Bu yazımızda Artifica Teknoloji bünyesinde çalışan bir veri bilimci gözünden öğrenim aktarımı yaklaşımını şirketimizin bünyesinde nasıl kullandığımızı ve nasıl süreçlerden geçtiğimizi aktarmaya çalıştık. Öğrenme aktarımının yapay zeka modellerine olan katkıları ve nasıl kullandığıyla alakalı deneyimlerimizi paylaştık. Ayrıca derin öğrenme modelleri kurulurken sıklıkla karşılaşılan problemler ve çözümlerine de değinmeye çalıştık.
Artifica Teknolojinin yapay zeka tabanlı ürünü olan AI-Commerce’i geliştirirken geçtiğimiz aşamaları ve karşılaştığımız zorlukları sizinle paylaşmak istedik. Ürün geliştirme sürecimizde yapay zeka tarafında edindiğimiz tecrübelerimizi aktarırken siz de bu serüvene ortak olabilirsiniz. Bir sonraki yazımızda görüşmek üzere.
Müstecep Berca Akbayır
Veri Bilimci
Bu yazının orjinaline erişmek için tıklayın: https://medium.com/@bercaakbayir/%C3%B6%C4%9Frenme-aktariminin-transfer-learning-ger%C3%A7ek-hayat-problemleri%CC%87nde-kullanimi-95c08425bd1e
Kaynakça:
https://dergipark.org.tr/tr/download/article-file/833620
https://keras.io/guides/transfer_learning/
https://www.spiceworks.com/tech/artificial-intelligence/articles/articles-what-is-transfer-learning/